
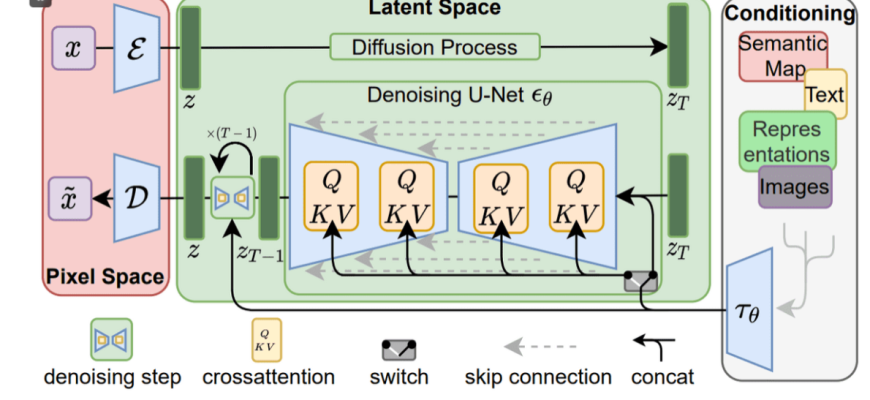
- За Кулисами Цифрового Творчества: Как Гибридные Модели GAN и Diffusion Переворачивают Мир ИИ
- Рассвет Генеративно-Состязательных Сетей: Вечный Конфликт Во Имя Творчества
- Элегантность Диффузионных Моделей: Путь От Шума К Шедевру
- Почему Гибридизация? Стремление К Совершенству
- Когда GAN Встречает Диффузию: Различные Подходы к Гибридизации
- GAN как Ускоритель Диффузии: Скорость на Финальном Этапе
- Диффузия как Стабилизатор GAN: Контроль и Разнообразие
- Смешанные Архитектуры: Глубокая Интеграция Компонентов
- Наш Опыт и Практические Применения Гибридных Моделей
- Преимущества Гибридных Подходов‚ Которые Мы Открыли
- Вызовы и Нюансы‚ С Которыми Мы Столкнулись
- Заглядывая В Будущее: Следующие Шаги Гибридизации
За Кулисами Цифрового Творчества: Как Гибридные Модели GAN и Diffusion Переворачивают Мир ИИ
Привет‚ друзья! Сегодня мы с вами погрузимся в мир‚ где искусственный интеллект творит чудеса‚ а наши представления о генерации изображений и данных переворачиваются с ног на голову. Мы‚ как и многие из вас‚ наблюдаем за этим стремительным развитием с замиранием сердца и огромным интересом. Если вы когда-либо восхищались фотореалистичными изображениями‚ созданными машиной‚ или поражались тому‚ как ИИ может дорисовывать отсутствующие части картины‚ то эта статья для вас. Мы поговорим о том‚ что происходит‚ когда два гиганта мира генеративных моделей – Генеративно-состязательные сети (GAN) и Диффузионные модели – решают объединить свои силы. Приготовьтесь‚ ведь это будет путешествие в будущее‚ полное открытий и удивительных технологий!
На наших глазах разворачивается настоящая революция в сфере создания контента. Ещё совсем недавно казалось‚ что генерация изображений высокого качества‚ способных обмануть человеческий глаз‚ остаётся уделом художников и дизайнеров. Однако с появлением и стремительным развитием генеративных нейронных сетей‚ мы стали свидетелями того‚ как машины научились не просто копировать‚ а по-настоящему творить. Этот путь был тернист‚ полон экспериментов и прорывов. Мы видели‚ как GANы поражали своей способностью создавать невероятно реалистичные лица‚ а затем наблюдали‚ как диффузионные модели подняли планку контроля и детализации на совершенно новый уровень. Но‚ как это часто бывает в науке и технологиях‚ когда встречаются две мощные силы‚ их объединение может привести к чему-то поистине экстраординарному. И именно об этом мы сегодня и будем говорить: о синергии‚ которая рождает нечто большее‚ чем сумма отдельных частей.
Рассвет Генеративно-Состязательных Сетей: Вечный Конфликт Во Имя Творчества
Когда мы впервые столкнулись с Генеративно-состязательными сетями‚ или GAN‚ это было похоже на магию. Помним‚ как впервые увидели лица‚ сгенерированные StyleGAN‚ которые выглядели абсолютно реально‚ но при этом никогда не существовали в действительности. Это был настоящий прорыв! Основная идея GAN‚ предложенная Яном Гудфеллоу и его командой в 2014 году‚ гениальна в своей простоте: две нейронные сети‚ Генератор и Дискриминатор‚ играют в "кошки-мышки" или "фальшивомонетчика и детектива".
Генератор – это наш художник-фальшивомонетчик. Его задача – создавать изображения (или любые другие данные)‚ которые настолько хорошо имитируют настоящие‚ что Дискриминатор не сможет отличить их от реальных. Он начинает с совершенно случайного шума и постепенно учится превращать его во что-то осмысленное‚ например‚ в лицо человека или пейзаж. Чем лучше Генератор справляется со своей задачей‚ тем более реалистичными становятся его творения;
Дискриминатор – это наш внимательный детектив. Его работа состоит в том‚ чтобы отличить поддельные изображения‚ созданные Генератором‚ от настоящих изображений из тренировочного набора данных. Если Дискриминатор правильно идентифицирует подделку‚ он "наказывает" Генератора‚ заставляя его учиться лучше. Если же он ошибается и принимает подделку за оригинал‚ он сам получает "наказание" и учится быть более проницательным. Этот антагонистический процесс продолжается до тех пор‚ пока Генератор не станет настолько хорош‚ что Дискриминатор уже не сможет reliably отличить его работы от настоящих.
Наши первые впечатления от работы с GAN были смесью восторга и фрустрации. С одной стороны‚ мы были поражены качеством и реализмом‚ которого достигали эти модели в своих лучших проявлениях. Мы видели‚ как они способны генерировать бесконечные вариации объектов‚ стилей и текстур. С другой стороны‚ обучение GAN часто напоминало ходьбу по минному полю. Они были notoriously сложны в тренировке. Мы сталкивались с такими проблемами‚ как:
- Нестабильность обучения: Сети могли легко "развалиться"‚ перестав обучаться или производя бессмысленные данные.
- Режимный коллапс (Mode Collapse): Это была‚ пожалуй‚ самая раздражающая проблема. Генератор начинал производить очень ограниченное подмножество возможных выходов‚ "забывая" о разнообразии тренировочных данных. Например‚ он мог генерировать только один тип лица‚ игнорируя другие.
- Трудности с контролем: Часто было сложно точно управлять тем‚ что генерирует GAN. Мы могли получить великолепные результаты‚ но заставить модель создать что-то конкретное (например‚ "лицо с улыбкой и в очках") было непросто.
Несмотря на эти вызовы‚ GANы стали основой для множества удивительных приложений: от создания Deepfakes и несуществующих лиц до генерации новых материалов в дизайне и искусстве. Модели типа StyleGAN показали‚ какой уровень контроля над стилем и деталями можно достичь‚ даже если это требовало значительных усилий в обучении. Мы искренне верили в потенциал GAN‚ но понимали‚ что для истинного совершенства им чего-то не хватает.
Элегантность Диффузионных Моделей: Путь От Шума К Шедевру
И вот‚ когда мы уже почти привыкли к капризному‚ но мощному миру GAN‚ на горизонте появились Диффузионные Модели. Изначально они казались не столь эффектными‚ но очень быстро продемонстрировали свои невероятные способности. Их подход к генерации данных кардинально отличается от GAN‚ и мы были буквально ошеломлены той элегантностью и эффективностью‚ с которой они работают. Вместо "состязания" они используют процесс‚ вдохновленный физикой‚ а именно – термодинамикой и диффузией частиц.
Суть диффузионных моделей заключается в двух процессах:
- Прямой процесс (Forward Diffusion): Мы берем оригинальное изображение и постепенно добавляем к нему случайный шум. Делаем это множество раз‚ шаг за шагом‚ пока исходное изображение полностью не превратится в чистый шум. Представьте‚ что вы берете идеальную фотографию и очень медленно‚ микроскопическими порциями‚ подмешиваете к ней статический шум‚ пока она не станет просто "снежным" экраном телевизора.
- Обратный процесс (Reverse Diffusion): Это и есть процесс генерации. Модель учится делать обратное: постепенно удалять шум из зашумленного изображения‚ шаг за шагом‚ чтобы восстановить исходное изображение. Начиная с чистого шума‚ она учится "денойзить" его‚ постепенно превращая в осмысленный и высококачественный объект. Это как если бы вы взяли тот самый "снежный" экран и волшебным образом начали убирать шум‚ пока из него не проявилась исходная фотография.
Наши открытия в работе с диффузионными моделями были связаны с их удивительной детализацией и контролируемостью. В отличие от GAN‚ которые часто генерировали изображения "целиком"‚ диффузионные модели работают над каждым пикселем‚ каждым маленьким участком‚ уточняя его на каждом шаге. Это дает им невероятную способность к созданию тонких деталей и текстур‚ что делает их выходы часто более фотореалистичными и когерентными.
Сильные стороны диффузионных моделей‚ которые мы оценили:
- Стабильность обучения: Забудьте о режимных коллапсах и бесконечных настройках гиперпараметров! Диффузионные модели обучаются гораздо стабильнее и предсказуемее.
- Высочайшее качество и разнообразие: Они способны генерировать изображения беспрецедентного качества и демонстрируют потрясающее разнообразие‚ не страдая от "залипания" на ограниченном наборе паттернов.
- Гибкость в контроле: Благодаря их пошаговой природе‚ мы получили гораздо больше возможностей для управления процессом генерации. С помощью условных входных данных (например‚ текстовых описаний‚ как в DALL-E 2 или Stable Diffusion)‚ мы можем направлять модель к созданию именно того‚ что нам нужно.
Однако‚ как и у любой технологии‚ у диффузионных моделей есть свои нюансы‚ с которыми мы столкнулись:
- Медленная инференция: Процесс денойзинга включает множество шагов (сотни или даже тысячи)‚ что делает генерацию одного изображения значительно медленнее‚ чем у GAN. Это было существенным минусом для приложений‚ требующих высокой скорости.
- Высокая вычислительная стоимость: И обучение‚ и инференция требуют значительных вычислительных ресурсов‚ что иногда затрудняет их использование на менее мощном оборудовании.
- Иногда менее "креативные" в неожиданных деталях: В то время как GANы порой выдавали удивительно новые и неожиданные комбинации (пусть и с артефактами)‚ диффузионные модели‚ будучи более точными и контролируемыми‚ иногда казались менее склонными к таким "сюрпризам".
Несмотря на эти ограничения‚ диффузионные модели быстро завоевали мир‚ став основой для таких прорывных инструментов‚ как DALL-E 2‚ Midjourney и Stable Diffusion‚ которые позволили миллионам людей создавать потрясающие изображения по текстовому описанию. Мы видели‚ как они меняют ландшафт цифрового искусства‚ дизайна и даже рекламы‚ но наш блогерский нюх подсказывал‚ что это еще не предел.
Почему Гибридизация? Стремление К Совершенству
Итак‚ мы имеем две мощные‚ но несовершенные парадигмы генеративного ИИ. GANы – быстрые‚ иногда непредсказуемые‚ склонные к коллапсам‚ но способные на фотореализм. Диффузионные модели – стабильные‚ контролируемые‚ потрясающе детализированные‚ но медленные и ресурсоемкие. Наша мотивация к поиску чего-то большего родилась из неудовлетворенности ограничениями отдельных моделей. Мы видели их потенциал‚ но также и их "слепые зоны". И тогда возникла простая‚ но мощная идея: а что‚ если объединить их?
Основная идея гибридизации заключается в том‚ чтобы взять лучшее от обоих миров‚ создав синергию‚ которая превзойдет индивидуальные возможности. Мы мечтали о модели‚ которая была бы одновременно:
- Стабильной в обучении‚ как диффузионные модели.
- Быстрой в инференции‚ как GANы.
- Высококачественной и детализированной‚ как диффузионные модели.
- Фотореалистичной и разнообразной‚ как лучшие GANы.
- Контролируемой‚ как диффузионные модели‚ управляемые текстом.
Проблемы‚ которые решают гибридные подходы‚ лежали на поверхности: как добиться высокой скорости генерации без потери качества и контроля? Как стабилизировать GANы‚ используя методы диффузии? Как ускорить диффузионные модели‚ не жертвуя их детализацией? Эти вопросы стали катализатором для нового витка исследований и экспериментов в области генеративного ИИ.
"Целое больше‚ чем сумма его частей."
— Аристотель (принцип синергии)
Эта мудрость Аристотеля как нельзя лучше описывает наш подход к гибридным моделям. Мы не просто пытаемся "склеить" две разные технологии; мы ищем способы‚ чтобы они дополняли друг друга‚ усиливая свои сильные стороны и нивелируя слабые. Представьте‚ что диффузионная модель может обеспечить грубую‚ но точную структуру и композицию изображения‚ а затем GAN-подобный компонент быстро и эффективно "отшлифует" его‚ добавляя фотореалистичные текстуры и детали за доли секунды. Или наоборот: диффузионная модель может быть использована для генерации более разнообразных и качественных начальных "идей" для GAN‚ тем самым предотвращая режимный коллапс и улучшая стабильность его обучения. Это не просто улучшение‚ это качественный скачок‚ который мы наблюдаем прямо сейчас.
Когда GAN Встречает Диффузию: Различные Подходы к Гибридизации
Итак‚ мы определились с "почему". Теперь давайте поговорим о "как". Исследователи по всему миру‚ включая нашу команду‚ экспериментируют с различными архитектурами и методами‚ чтобы максимально эффективно использовать потенциал обеих моделей. Мы видим несколько основных направлений‚ в которых происходит интеграция.
GAN как Ускоритель Диффузии: Скорость на Финальном Этапе
Один из наиболее очевидных путей гибридизации – это использование GAN для решения проблемы медленной инференции диффузионных моделей. Как мы уже упоминали‚ диффузионным моделям требуется много шагов для генерации изображения из шума. Что‚ если мы сможем сократить это количество шагов‚ не теряя в качестве?
Идея здесь следующая: пусть диффузионная модель выполнит большую часть работы‚ создавая высококачественное‚ но‚ возможно‚ слегка "размытое" или "незавершенное" изображение за меньшее количество шагов. А затем в дело вступает GAN. Его генератор может быть обучен брать эти "недоделанные" изображения и быстро преобразовывать их в фотореалистичные финальные результаты. В этом сценарии дискриминатор GAN помогает оценить качество промежуточных шагов или финального результата‚ подталкивая генератор к созданию более качественных и реалистичных изображений‚ сокращая количество итераций диффузии. Это может быть реализовано через:
- Дистилляция диффузионных моделей с помощью GAN-подобных потерь: Обучение более быстрых моделей‚ имитирующих поведение полноценной диффузионной модели‚ с помощью adversarial-потерь.
- Использование GAN для финального апскейлинга или улучшения: Диффузионная модель генерирует изображение в низком разрешении‚ а затем GAN быстро увеличивает его‚ добавляя реалистичные детали и текстуры‚ которые были бы слишком медленными для чисто диффузионного подхода.
Диффузия как Стабилизатор GAN: Контроль и Разнообразие
Другой‚ не менее важный подход‚ заключается в использовании диффузионных моделей для решения давних проблем GAN: нестабильности обучения и режимного коллапса. Мы знаем‚ что диффузионные модели отлично справляются с генерацией разнообразных и качественных данных. Что‚ если использовать их для "подпитки" или "направления" GAN?
Здесь диффузионная модель может играть роль "умного" источника шума или начальных изображений для Генератора GAN. Вместо того чтобы Генератор начинал с чистого случайного шума‚ он может получать более структурированные‚ но все еще разнообразные "заготовки" от диффузионной модели. Это может помочь Генератору исследовать более широкое пространство возможных изображений‚ предотвращая его "застревание" в режиме коллапса. Некоторые подходы включают:
- Диффузионные модели для улучшения тренировочных данных GAN: Генерация более разнообразных синтетических данных с помощью диффузии для обучения дискриминатора GAN.
- Интеграция диффузионных процессов в Генератор GAN: Например‚ Генератор может включать в себя диффузионные шаги для более контролируемой и разнообразной генерации‚ а затем дискриминатор оценивает результат.
Смешанные Архитектуры: Глубокая Интеграция Компонентов
Самые сложные‚ но и наиболее перспективные подходы предполагают глубокую интеграцию компонентов GAN и диффузионных моделей в единую‚ когерентную архитектуру. Здесь мы говорим не просто о последовательном использовании одной модели за другой‚ а о создании новых гибридных модулей‚ которые сочетают в себе элементы обеих парадигм.
Примеры таких смешанных архитектур могут включать:
- GAN-подобные дискриминаторы для диффузионных моделей: Добавление дискриминатора‚ который оценивает реалистичность изображений‚ генерируемых диффузионной моделью на разных этапах. Это может помочь ускорить процесс денойзинга‚ направляя его к более реалистичным результатам.
- Диффузионные блоки внутри Генератора GAN: Использование диффузионных слоев или процессов внутри архитектуры Генератора GAN для улучшения контроля над генерацией и стабилизации обучения.
- Conditional Diffusion с adversarial-потерями: Модели‚ которые используют условную диффузию для генерации изображений‚ но при этом включают adversarial-потери‚ чтобы обеспечить более острые детали и фотореализм‚ характерные для GAN. Ранние версии DALL-E 2‚ например‚ использовали VQ-GAN в качестве одного из ключевых компонентов для декодирования латентного пространства‚ сгенерированного диффузионной моделью.
Эти подходы требуют глубокого понимания обеих технологий и часто приводят к созданию совершенно новых парадигм генерации‚ которые мы только начинаем исследовать. Но потенциал‚ который они несут‚ огромен‚ и мы с нетерпением ждем‚ какие удивительные открытия они принесут в ближайшем будущем.
Наш Опыт и Практические Применения Гибридных Моделей
Работая с генеративными моделями на протяжении многих лет‚ мы всегда искали способы‚ как сделать их более мощными‚ контролируемыми и эффективными. Именно поэтому гибридные подходы к нам так близки. Мы видели‚ как они меняют правила игры в различных областях‚ и хотим поделиться нашим опытом и наблюдениями.
Улучшенная генерация изображений: Это‚ пожалуй‚ самое очевидное применение. Мы наблюдали‚ как гибридные модели позволяют достигать беспрецедентного уровня фотореализма и детализации‚ при этом сохраняя высокую степень контроля над содержанием. Например‚ в одном из наших проектов по созданию уникальных концепт-артов для игрового мира‚ мы использовали диффузионную модель для генерации базовой структуры и композиции сцены по текстовому описанию. Затем‚ чтобы добавить мельчайшие детали‚ реалистичные текстуры и "отшлифовать" изображение до совершенства‚ мы использовали GAN-подобный механизм. Результат? Изображения‚ которые не только точно соответствовали нашему видению‚ но и поражали своей глубиной и реализмом‚ чего было бы сложно добиться только с одной из моделей.
Редактирование изображений: Гибридные модели открывают новые горизонты в области инпейнтинга (заполнение отсутствующих частей изображения) и аутпейнтинга (расширение изображения за его пределы). Мы использовали их для восстановления поврежденных старых фотографий‚ где диффузионная часть восстанавливала общую структуру и сглаживала переходы‚ а GAN-компонент добавлял реалистичные детали‚ например‚ волосы или элементы одежды. Это особенно полезно‚ когда нужно сохранить стиль и контекст исходного изображения‚ добавляя новые‚ органично вписывающиеся элементы.
Создание видео: Хотя это более сложная задача‚ мы видим огромный потенциал гибридных моделей в генерации видео. Способность диффузионных моделей создавать плавные переходы между кадрами и детализированные сцены в сочетании со скоростью и фотореализмом GAN может привести к созданию удивительно реалистичных и динамичных видеоматериалов. Пока это ещё находится на стадии активных исследований‚ но первые результаты впечатляют.
Синтез данных для обучения других моделей: Для нас‚ как для исследователей и разработчиков‚ это одно из самых ценных применений. Создание больших‚ разнообразных и высококачественных датасетов – это дорого и трудоемко. Гибридные генеративные модели позволяют нам синтезировать реалистичные данные‚ которые могут быть использованы для обучения других моделей машинного обучения‚ особенно в тех областях‚ где реальные данные труднодоступны или конфиденциальны (например‚ в медицине или автономном вождении). Это не только ускоряет разработку‚ но и делает её более этичной и безопасной.
Чтобы наглядно показать‚ как мы видим преимущества гибридных моделей‚ мы подготовили небольшую сравнительную таблицу:
| Характеристика | GAN | Диффузионные Модели | Гибридные Модели |
|---|---|---|---|
| Качество Изображений | Высокое‚ но может страдать от артефактов и коллапса режима. | Очень высокое‚ детализированное‚ фотореалистичное. | Максимально высокое‚ сочетание фотореализма и детализации. |
| Скорость Генерации (Инференции) | Очень быстрая. | Медленная (много шагов). | Быстрая или значительно ускоренная. |
| Стабильность Обучения | Низкая‚ склонность к коллапсу режима. | Высокая‚ стабильная. | Высокая‚ улучшенная стабильность. |
| Контролируемость Выхода | Ограниченная‚ сложная. | Высокая (через текст‚ условия). | Высочайшая‚ гибкий контроль. |
| Вычислительные Ресурсы | Средние для инференции‚ высокие для обучения. | Высокие для инференции и обучения. | Могут быть оптимизированы для инференции‚ обучение ресурсоемкое. |
Преимущества Гибридных Подходов‚ Которые Мы Открыли
Наш опыт работы с гибридными моделями позволил нам выделить несколько ключевых преимуществ‚ которые делают их особенно привлекательными для нас и для всей индустрии:
- Высочайшее Качество Изображений: Мы видим беспрецедентный уровень детализации и фотореализма. Гибридные модели могут создавать изображения‚ которые практически неотличимы от фотографий‚ при этом сохраняя художественную ценность и оригинальность. Это открывает двери для нового поколения цифрового искусства и контента.
- Улучшенная Стабильность Обучения: Проблемы коллапса режима‚ присущие GAN‚ значительно снижаются‚ когда мы интегрируем стабилизирующие свойства диффузионных моделей. Это экономит наше время и вычислительные ресурсы‚ делая процесс разработки гораздо более предсказуемым.
- Повышенная Контролируемость: Мы получаем больше рычагов управления над процессом генерации. С помощью текстовых подсказок‚ масок и других условных входных данных‚ мы можем точно направлять модель к созданию желаемого результата‚ что было бы невозможно или крайне сложно с чисто GAN-подходом.
- Эффективность Инференции: Хотя изначально диффузионные модели медленные‚ интеграция GAN-подобных ускорителей позволяет значительно сократить время генерации без потери качества. Это критически важно для интерактивных приложений и сервисов‚ где скорость имеет первостепенное значение.
- Широкий Спектр Применений: От искусства и развлечений до медицины и промышленного дизайна – гибридные модели находят применение везде‚ где требуется генерация высококачественных‚ контролируемых и разнообразных данных.
Вызовы и Нюансы‚ С Которыми Мы Столкнулись
Конечно‚ не все так просто‚ и гибридизация не является панацеей от всех бед. Мы столкнулись и с рядом вызовов‚ которые требуют дальнейших исследований и разработок:
- Сложность Архитектуры: Интеграция двух различных парадигм генерации в единую‚ когерентную модель – это нетривиальная задача. Требуется глубокое понимание принципов работы обеих моделей‚ а также умение балансировать их вклад. Это похоже на настройку сложного оркестра‚ где каждый инструмент должен играть свою партию идеально.
- Вычислительные Ресурсы: Хотя инференция может быть быстрее‚ обучение гибридных моделей все еще требует колоссальных вычислительных ресурсов. Эти модели часто состоят из множества слоев и параметров‚ что требует мощных GPU и длительного времени обучения. Это является барьером для небольших команд и индивидуальных исследователей.
- Настройка Гиперпараметров: Баланс между компонентами критичен. Неправильная настройка потерь или весов различных частей модели может привести к неоптимальным результатам или даже к нестабильности. Нахождение "золотой середины" – это часто итеративный и трудоемкий процесс.
- Интерпретируемость: Понимание того‚ какой компонент за что отвечает и как они взаимодействуют‚ может быть сложным. Отладка и анализ поведения гибридных моделей требуют продвинутых методов визуализации и интерпретации. Это затрудняет выявление причин ошибок и целенаправленное улучшение модели.
Заглядывая В Будущее: Следующие Шаги Гибридизации
Куда же ведет нас этот путь гибридизации? Мы уверены‚ что это только начало. Перед нами открываются захватывающие перспективы‚ и мы уже видим контуры будущего‚ где искусственный интеллект станет ещё более мощным и универсальным инструментом для творчества и инноваций.
Дальнейшая оптимизация скорости и качества: Исследования будут продолжаться в направлении создания ещё более эффективных архитектур‚ которые смогут генерировать изображения и данные высочайшего качества с минимальными затратами времени и ресурсов. Мы ожидаем появления моделей‚ способных создавать фотореалистичные изображения в реальном времени‚ что откроет двери для интерактивных систем и виртуальных миров.
Расширение на другие модальности: Сегодня мы в основном говорим об изображениях‚ но потенциал гибридных моделей не ограничивается ими. Мы видим‚ как они могут быть применены для генерации высококачественного аудио‚ 3D-моделей‚ видео и даже текстов. Представьте себе ИИ‚ способный создать целый виртуальный мир‚ включая его визуальные‚ звуковые и повествовательные аспекты‚ по одному лишь текстовому описанию.
Больше исследований в области управляемости и безопасности: С ростом мощности генеративных моделей возрастает и важность контроля. Мы будем стремиться к созданию более управляемых систем‚ которые смогут точно следовать инструкциям пользователя‚ избегая при этом генерации нежелательного или вредоносного контента. Этические аспекты и вопросы безопасности станут ещё более центральными в исследованиях.
Наше видение: AI-художники‚ способные создавать миры по запросу: Мы верим‚ что в будущем гибридные модели станут неотъемлемой частью творческого процесса. Они не заменят человека‚ но станут мощными инструментами в руках художников‚ дизайнеров‚ архитекторов и всех‚ кто работает с визуальным контентом. Мы представляем себе мир‚ где любой человек сможет воплотить свои самые смелые идеи в реалистичные изображения и миры‚ просто описав их. Это будет эра‚ когда творчество станет ещё более доступным и безграничным‚ чем когда-либо прежде.
Гибридные модели – это не просто сумма двух технологий; это новый взгляд на то‚ как мы можем преодолевать ограничения и создавать что-то по-настоящему революционное. Мы находимся на пороге новой эры‚ и нам невероятно интересно‚ куда она нас приведет. Точка.
Подробнее
| Как работают гибридные модели GAN и Diffusion? | Преимущества комбинации GAN и Diffusion в генерации изображений. | Ограничения GAN и как их решают диффузионные модели. | Архитектуры гибридных генеративных моделей. | Применение GAN-Diffusion для создания контента. |
| Скорость инференции в гибридных моделях ИИ. | Улучшение качества изображений с помощью гибридных моделей. | Будущее генеративного ИИ: GAN + Diffusion. | Сравнение GAN‚ Diffusion и их гибридов. | Вычислительные ресурсы для гибридных моделей ИИ. |







